
The goal of this project was to create an AI-driven recommendation engine to assist guidance professionals in advising accurate career trajectories to their clients. Given the input of a new resume, could the system recommend new roles and skills for the client to progress in their career?
This project was conducted in collaboration with a local Seattle startup. The dataset was provided by a SQL database in the form of raw unformatted resume data.


Exploring the data:
The dataset contained 83,000 unique users.

Challenges:
Ambiguous and subjective resume content
- Account Manager vs Account Management
- Computer Scientist vs Software Engineer
- Buyer vs Vendor Manager
- Microsoft Word vs Word vs MS Word
Horizontal and vertical target:
Horizontal: Similar fields or industries
- Accounting to Human Resources
- Mechanical Engineer to Software Engineer
Vertical: Experience level
- Junior to Senior
- Supervisor to Manager
Step 1:
The first stage of the data from relies on a process called cosine similarity. Essentially this mean that we compare two vectors with one another and score how similar they are. In this instance we will compare the matrix that represents the users resume with the database of job titles and score how closely suited they are for each role.
Some data cleaning was required before we could construct the feature matrix. We used tf–idf to analyse the words within each resume. We developed a scrub list to remove filler and irrelevant words.

Job title feature matrix
- X axis - job title keywords
- Y axis - User id
- Data - keyword frequency.
Step 2:
Principal component analysis (PCA) was used to reduce the dimensionality of the matrix. This reduces amount of features and allows the clustering algorithm to run more efficiently
Resulting matrix after PCA fed into an agglomerative clustering algorithm.
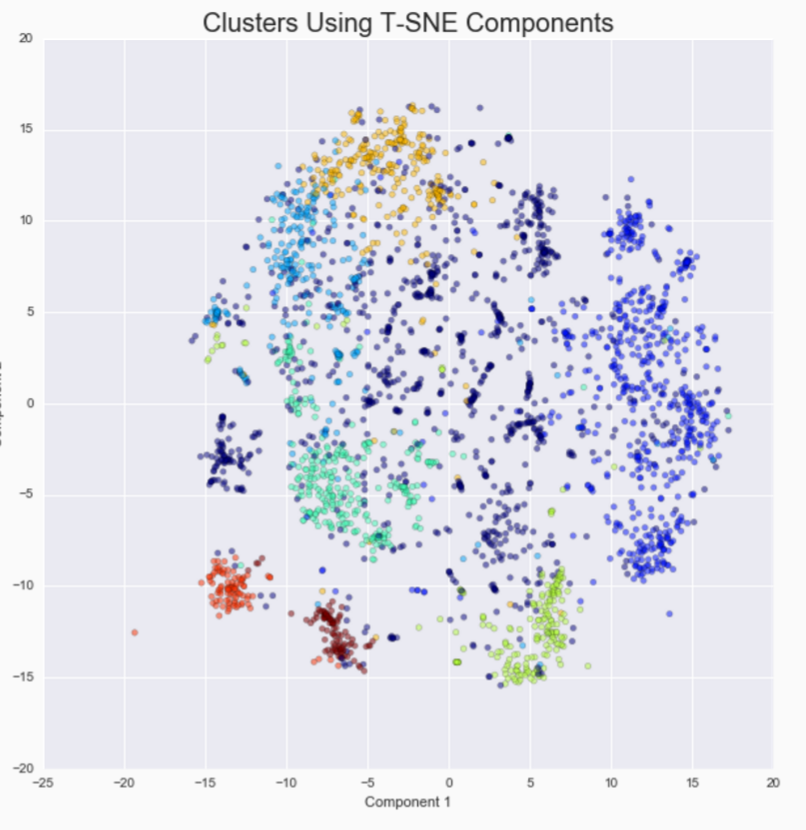
Clusters represent jobs most related by skills keywords
Intracluster recommendations = vertical career movement (usually)
Intercluster recommendations = horizontal career movement (again, usually)
Cluster 0 - Business, health, academia, labor
Cluster 1 - Software, data analysis, tech
Cluster 2 - Management, administration
Cluster 3 - Marketing and arts
Cluster 4 - Finance
Cluster 5 - PR, brand representative, service
Cluster 6 - Recruiting
Cluster 7 - Human Resources

Job Title Clustering Dendrogram
Step 3:
To help aid the efficiency of the engine, we trained a multinomial logistic regression model to predict cluster association when a new user was added to the system. This enabled quicker response time since only the new resume would be analysed before a prediction could be made.
In production, the model would be retrained on a scheduled basis, enabling updates to be added to the job title feature matrix.
The data flow:
- A new user uploads custom resume to the system. The users text is imported, vectorized, and decomposed using PCA.
- The logistic regression model is used against the user’s feature vector to predict a cluster number.
- Within the engine, a python function extracts the key job titles and skills from within the cluster and prints a job report for the user.

Example report of a closely associated field

Example report showing a distant recommendation
Results:
Upon completion, the recommender engine produce reasonable results and providing suggested career trajectories and skills.
Further refinements:
- Standardized input format for resume data
- Improve jobs dataset from external data sources, ie: LinkedIn
- Additional refinement on feature engineering and keyword filtering
- Incorporate distributed systems and big data architecture at scale